Приклад 1. Лабораторна робота. Базова статистика в R
Якщо R-статистика не встановлена, то завантажити її з сайту r-project.org та встановити. Можна завантажити та встановити R-Studio або використати її веб-версію)*.
Базова статистика в R
Завдання
Для даної вибірки розрахувати наступні характеристики: середнє значення, вибіркову дисперсію, стандартне відхилення, медіану, довірчі інтервали для середнього та дисперсії.
Виконання
Введення даних:
Масив даних=c(Список значень)
Середнє значення:
$$\bar{X}=\frac{1}{n}\sum\limits_{i=1}^n {x_i}$$
Функція для розрахунку:
mean(Масив даних)
Вибіркова дисперсія:
$$s^2=\frac{1}{n-1}\sum\limits_{i=1}^n( x_i-\bar{x})^2$$
Функція для розрахунку:
var(Масив даних)
Вибіркове стандартне відхилення:
$$s=\sqrt{s^2}$$
Функція для розрахунку:
sd(Масив даних)
Медіана. :
median(Масив даних)
Розрахунок меж довірчого інтервалу для математичного очікування (середнього):
$$M_{min}=\bar{x}-\frac{t_{\alpha, n-1} \cdot s}{\sqrt{n}}$$
$$M_{min}=\bar{x}+\frac{t_{\alpha, n-1} \cdot s}{\sqrt{n}}$$
\(t_ {\alpha, n-1}\) — коефіцієнт розподілу Стьюдента з рівнем недостовірності α (звичайно вживають величину 5% (0.05), n-1 — кількість ступенів свободи, для звичайної виборки на одиницю менше кількості чисел у виборці.
Функція для розрахунку коефіцієнта Стьюдента*:
qt(1-α/2,n-1)
*В функції qt із-за недостатьої проробки програми використовується значення ймовірності 1-α/2 замість 1-α . (Чисельно двохстроннє t1-α/2,n-1 рівне односторонньому t1-α.n-1)
Розрахунок меж довірчого інтервалу для дисперсії:
$$\sigma_{max}=\frac{(n-1) \cdot s^2}{\chi^2_{\alpha/2,n-1}}$$
$$\sigma_{min}=\frac{(n-1) \cdot s^2}{\chi^2_{1-\alpha/2,n-1}}$$
\(\chi^2_{1-\alpha/2,n-1}\) і \(\chi^2_{\alpha/2,n-1}\) — коефіцієнти розподілу χ2 з відповідними рівнями недостовірності та кількістю степеней свободи.
Функція для розрахунку коефіцієнта χ2:
qchisq(довірчий рівень,n-1)
Візуальне представлення результатів розрахунку
Побудова діаграми розмаху:
Функція для розрахунку:
boxplot(Масив даних)
Середнє значення на діаграмі:
abline(h=mean(Масив даних),col="Колір")
Межі довірчого інтервала на діаграмі:
abline(h=c(Mmin,Mmax),col="Колір")
Завдання для самопідготовки
Для кожної вибірки розрахувати характеристики, розрахувати межі довірчих інтервалив для середього та дисперсії, побудувати діаграми розмаху.
- x = 11, 12, 11, 13, 15;
- y = 43, 41, 42, 45;
- z = 22.5, 22.8, 22.7, 22.6, 22.8, 22.1.
Додаткові матеріали по темі
https://r-analytics.blogspot.com/2018/04/blog-post_28.html
http://stat.org.ua/statclasses/descriptive-statistics/
Порівняльні експерименти
Завдання
Дано дві виборки. Потрібно визначити, чи є між ними статистична різниця за допомогою t-тесту..
Інструкції
При парних випробуваннях можливі три принципово різні випадки:
а) порівняння двох виборок з однаковими дисперсіями;
б) порівняння двох виборок з різними дисперсіями;
в) парні спостереження (з холостим дослідом).
-
Перевірка на рівність дисперсій
Якщо у нас не явний випадок парних спостережень (випадок «в»), то спочатку треба перевірити гіпотезу про рівність дисперсій двох серій вимірювань. Нехай в нас є дві серії вимірювань: ![]() і
і ![]() — відповідно n замірів величини X та m замірів величини Y.
— відповідно n замірів величини X та m замірів величини Y.
Розраховуємо ![]() ,
, ![]() ,
, ![]() ,
, ![]() (лабораторна робота № 1, стор.3).
(лабораторна робота № 1, стор.3).
Гіпотеза про рівність дисперсій перевіряється за допомогою F-тесту, для цього розраховується F-статистика:
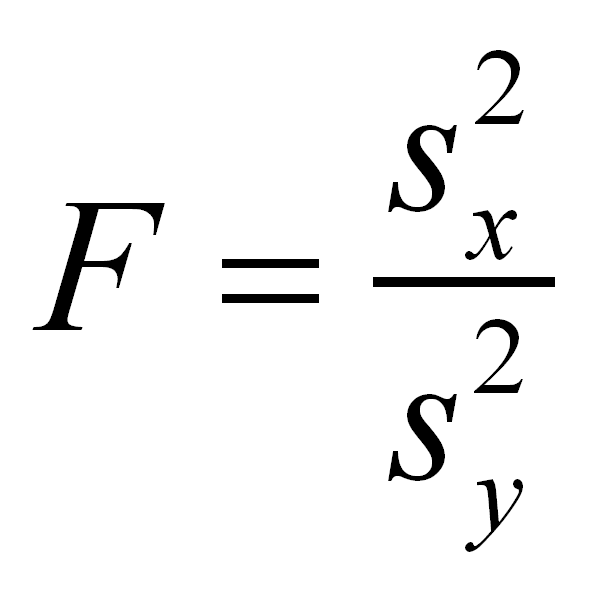 (більша дисперсія ділиться на меншу!)
(більша дисперсія ділиться на меншу!)
Якщо ![]() то статистично дисперсії X та Y рівні
то статистично дисперсії X та Y рівні
Якщо ![]() , то статистично дисперсії X та Y відрізняються
, то статистично дисперсії X та Y відрізняються
![]() — коефіцієнт F-розподілу (F-критичне), $$\alpha$$ — рівень недостовірності,. β — кількість ступенів свободи виборки з більшою дисперсією, γ — кількість ступенів свободи виборки з меншою дисперсією. Кількість ступенів свободи на один менше ніж кількість вимірювань відповідної величини. Якщо
— коефіцієнт F-розподілу (F-критичне), $$\alpha$$ — рівень недостовірності,. β — кількість ступенів свободи виборки з більшою дисперсією, γ — кількість ступенів свободи виборки з меншою дисперсією. Кількість ступенів свободи на один менше ніж кількість вимірювань відповідної величини. Якщо ![]() , то виборки формально міняються місцями.
, то виборки формально міняються місцями.
Розрахунок за допомогою R-статистики:
Функція для проведення F-тесту:
var.test(x,y)
Дисперсія x повинна бути більшою ніж y.
Функція для розрахунку коефіцієнта F-розподілу:
qf(0.95,dfx,dfy)
Дисперсія x повинна бути більшою ніж y.
-
Випадок статистичної рівності дисперсій
Якщо дисперсії рівні, то наявність статистичної різниці виявляється наступними чином:
Перевірочна t-статистика визначається формулою:
$$t_{\nu}=\frac{|\bar{x}-\bar{y}|\cdot\sqrt{n+m-2}}{\sqrt{\frac{1}{n}+\frac{1}{m}}\cdot\sqrt{(n-1)\cdot s_x^2+(m-1)\cdot s_y^2}}$$
![]() — кількість ступенів свободи;
— кількість ступенів свободи;
![]() порівнюється з відповідним коефіцієнтом Стьюдента
порівнюється з відповідним коефіцієнтом Стьюдента ![]() (t-критичне) з рівнем недостовірності ймовірності α, та кількістю ступенів свободи \(\nu\).
(t-критичне) з рівнем недостовірності ймовірності α, та кількістю ступенів свободи \(\nu\).
Якщо ![]() , то між серіями вимірювань є статистична різниця;
, то між серіями вимірювань є статистична різниця;
Якщо ![]() , то між серіями вимірювань немає статистичної різниці.
, то між серіями вимірювань немає статистичної різниці.
Розрахунок за допомогою R-статистики:
Функція для проведення t-тесту:
t.test(x,y,var.equal=TRUE)
Дисперсія x повинна бути більшою ніж y.
Функція для розрахунку коефіцієнта t-розподілу:
qt(0.975,df)
df визначаєтся в результаті t-тесту.
-
Випадок статистичної нерівності дисперсій
Якщо дисперсії різні, то наявність статистичної різниці виявляється наступними чином:
Перевірочна статистика визначається формулою:
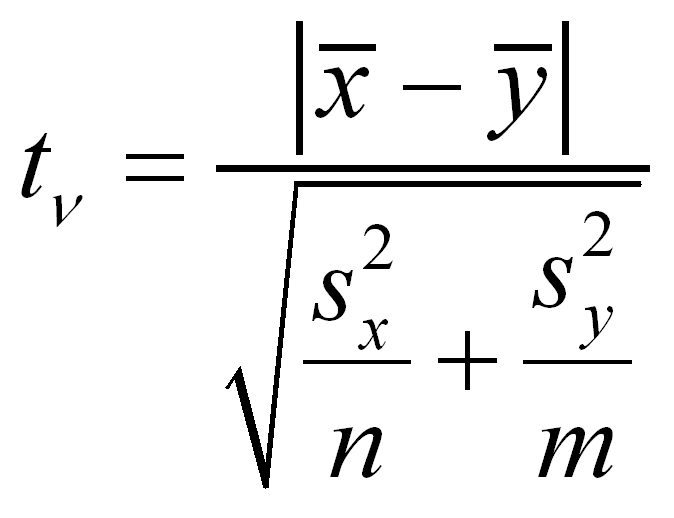
кількість ступенів свободи:
$$\nu=\left[\frac{\left(\frac{s_x^2}{n}+\frac{s_y^2}{n}\right)^2}{\frac{1}{n-1}\cdot\left(\frac{s_x^2}{n}\right)^2+\frac{1}{m-1}\cdot\left(\frac{s_y^2}{m}\right)^2}-2\right]$$
![]() порівнюється з відповідним коефіцієнтом Стьюдента
порівнюється з відповідним коефіцієнтом Стьюдента ![]() (t‑критичне) з рівнем недостовірності α, та кількістю ступенів свободи ν.
(t‑критичне) з рівнем недостовірності α, та кількістю ступенів свободи ν.
Якщо ![]() , то між серіями вимірювань є статистична різниця;
, то між серіями вимірювань є статистична різниця;
Якщо ![]() , то між серіями вимірювань немає статистичної різниці.
, то між серіями вимірювань немає статистичної різниці.
Розрахунок за допомогою R-статистики:
Функція для проведення t-тесту:
t.test(x,y,var.equal=FALSE)
Дисперсія x повинна бути більшою ніж y.
Функція для розрахунку коефіцієнта t-розподілу:
qt(0.975,df)
df визначаєтся в результаті t-тесту.
-
Порівняння з холостим дослідом
Третій випадок відрізняється від попередніх тим, що тут дисперсія апріорі однакова й немає сенсу її перевіряти.
Перевірочна статистика визначається формулою:
$$t_{n-1}=\frac{\bar{d}}{s_d}\cdot\sqrt{n}$$
де ![]() — середнє значень
— середнє значень ![]() ,
, ![]() — стандартне відхилення
— стандартне відхилення ![]() .
.
![]() порівнюється з відповідним коефіцієнтом Стьюдента
порівнюється з відповідним коефіцієнтом Стьюдента ![]() (t‑критичне) з рівнем недостовірності , та кількістю ступенів свободи n-1.
(t‑критичне) з рівнем недостовірності , та кількістю ступенів свободи n-1.
Якщо ![]() , то між серіями вимірювань є статистична різниця;
, то між серіями вимірювань є статистична різниця;
Якщо ![]() , то між серіями вимірювань немає статистичної різниці.
, то між серіями вимірювань немає статистичної різниці.
Розрахунок за допомогою R-статистики:
Функція для проведення t-тесту:
t.test(x,y,paired=TRUE)
Функція для розрахунку коефіцієнта t-розподілу:
qt(0.975,df)
df визначаєтся в результаті t-тесту.
Візуальне порівняння*
boxplot(x,y)
Звдання
Варіант № 1
-
Визначити, чи є різниця між двома виборками:
|
251.3 |
260.4 |
278.7 |
285.2 |
256.2 |
|||
|
336 |
338.8 |
337.2 |
338.3 |
338.7 |
339.1 |
338.4 |
337.7 |
Варіант № 2
-
Визначити, чи є різниця між двома виборками. Парні дослідження:
|
309.1 |
336.6 |
333.1 |
320.2 |
333.6 |
319.3 |
|
363.8 |
377.1 |
424.4 |
395.4 |
374.2 |
368.9 |
Варіант № 3
-
Визначити, чи є різниця між двома виборками:
|
183 |
193.6 |
192.3 |
188.3 |
192.5 |
187 |
201.4 |
190.2 |
199.9 |
|
189.7 |
199 |
217.4 |
221.8 |
194.7 |
211.6 |
195.1 |
В якості відповіді на завдання відправте лог виконання команд в R-статистиці
*Спробуйте визначити, чи є різниця між виборками на око, аналізуючи діаграму розмаху. Порівняйте з висновком, зробленим на основі розрахунку ;)